
Today’s big organizations are finding it difficult to store the rapidly growing data and access it for quick decision making. So Data storage and the Fastest Data analysis are the two biggest challenges faced by today’s organizations.
Organisations generate a huge amount of data which could be related to money transactions, social media, IP etc.To tackle these issue company must look at Hadoop-based Data Lake.
In this article, I will let you know how Hadoop-based Data Lake can solve the problem of storing huge amounts of data and give you fast access to saved data.
Hadoop-based Data Lake
Hadoop-based Data Lake is built using Hadoop. You can easily store your large amounts of data and make it accessible.
Hadoop uses Hadoop Distributed File System (HDFS). This top technology allows you to store the ultimate amounts of data of any format and type. HDFC- based Data Lake helps you to store unstructured, semi-structured or multi-structured data(for eg- you can easily store binary number from a sensor, image data, machine logos, and even flat-files).
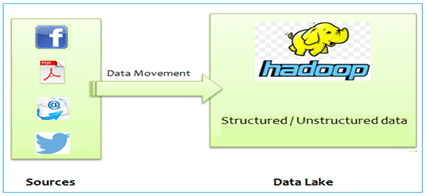
One more advantage of using Data Lake is once the data is stored, it can be accessed and processed in many different formats or patterns.
Hadoop-based Data Processing
Along with the data storage, Hadoop-based Data Lake also provides the parallel processing framework. Through this framework, you can easily process a large amount of data. Once the data is transferred into the Data Lake, data in the form of unstructured data and then it is changed into the structure with the help of Extract-Transform-Load process and it made available for fast processing and analysis with analytics and reporting technology that are mostly SQL based.
Business Scenario
Let me make more clear about the functioning of Hadoop-based Data Lake. Let’s look at the business scenario of the insurance Industry. This type of industries generate huge amounts of data (structured as well as unstructured).
Here is the typical use case. The sales manager of the company wants the data of how much premium was paid or claims being settled during last financial quarter. He wants to see the result of this query as quickly as possible.
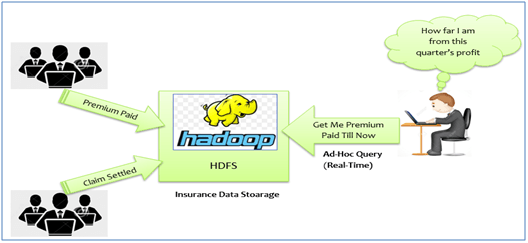
Steps Involved in solving this problem are
Step 1: All the data will be transferred to Hadoop Data Lake.
Step 2: Preprocess the data as per the requirement for the preprocess of data includes data cleaning and data validations.
Step 3: Make this data available to use with popular SQL-based BI and Analytics engines.
Let’s move to the more solution approach by Hadoop for the storage of large data and make fastest access to those data.
Apache Hive
This is an open source warehouse system built on top of Hadoop MapReduce framework for summarizing and analyzing of largest data. Apache Hive is the best for batch processing large amount of data.
Cloudera Impala
It is an MPP query engine that runs on Apache Hadoop. It gives you high performance, low-latency SQL queries on data Stored in Hadoop.
Over to You
Hadoop Technology is an open source software framework which is used to store a large amount of data in a distributed form which makes the processing of data faster. Hadoop Distributed File System is used to store any type of data in any format. In future, most of the companies must adopt this new technology.
Quick Search Our Blogs
Type in keywords and get instant access to related blog posts.
