
Are Large Language Models (LLMs) truly capable of thinking, or do they merely replicate what they have seen? Some say they only repeat information from their training, whereas others argue that they are the future of AI creativity.
What precisely is an LLM? How does a large language model work? To uncover the facts, we will examine how LLMs are constructed, how they learn, and the boundaries of their abilities. Among all large language model examples, Open AI’s GPT-5 stands as one of the very prominent LLM models.
In this blog, we will go through LLMs and understand them in detail.
Hit ‘Play’ Button & Tune Into The Blog!
Understanding Large Language Models
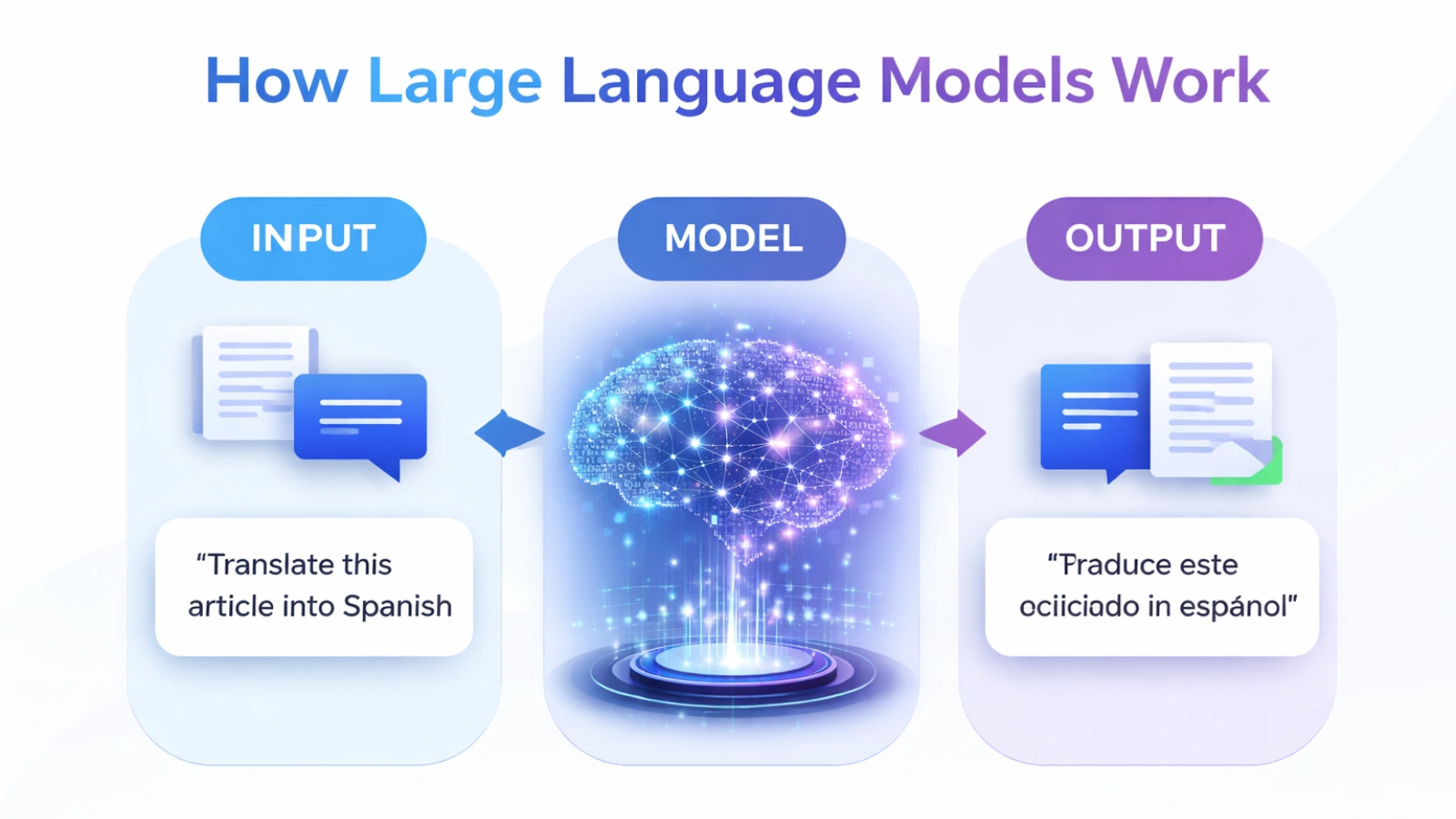
Large language models are a type of artificial intelligence tool designed for understanding, generating, and manipulating human language. They are referred to as large because they are trained on a vast amount of data, oftentimes comprising billions of words from various sources like books, articles, websites, and more.
These models are built on deep learning techniques, precisely neural networks, which enable them to learn patterns and structures in language.
An LLM’s core purpose is to generate the next word in a sequence of text, a sequence of words that have already been provided. Although this appears to be straightforward, it requires an enormous amount of context, grammar, meaning, and subtleties (such as sound/style). LLMs continue to become more advanced; now, LLMs produce text that is clear, appropriate for the current situation/subject, and sophisticated enough to be similar to what a human would write.
Key Components of Large Language Models
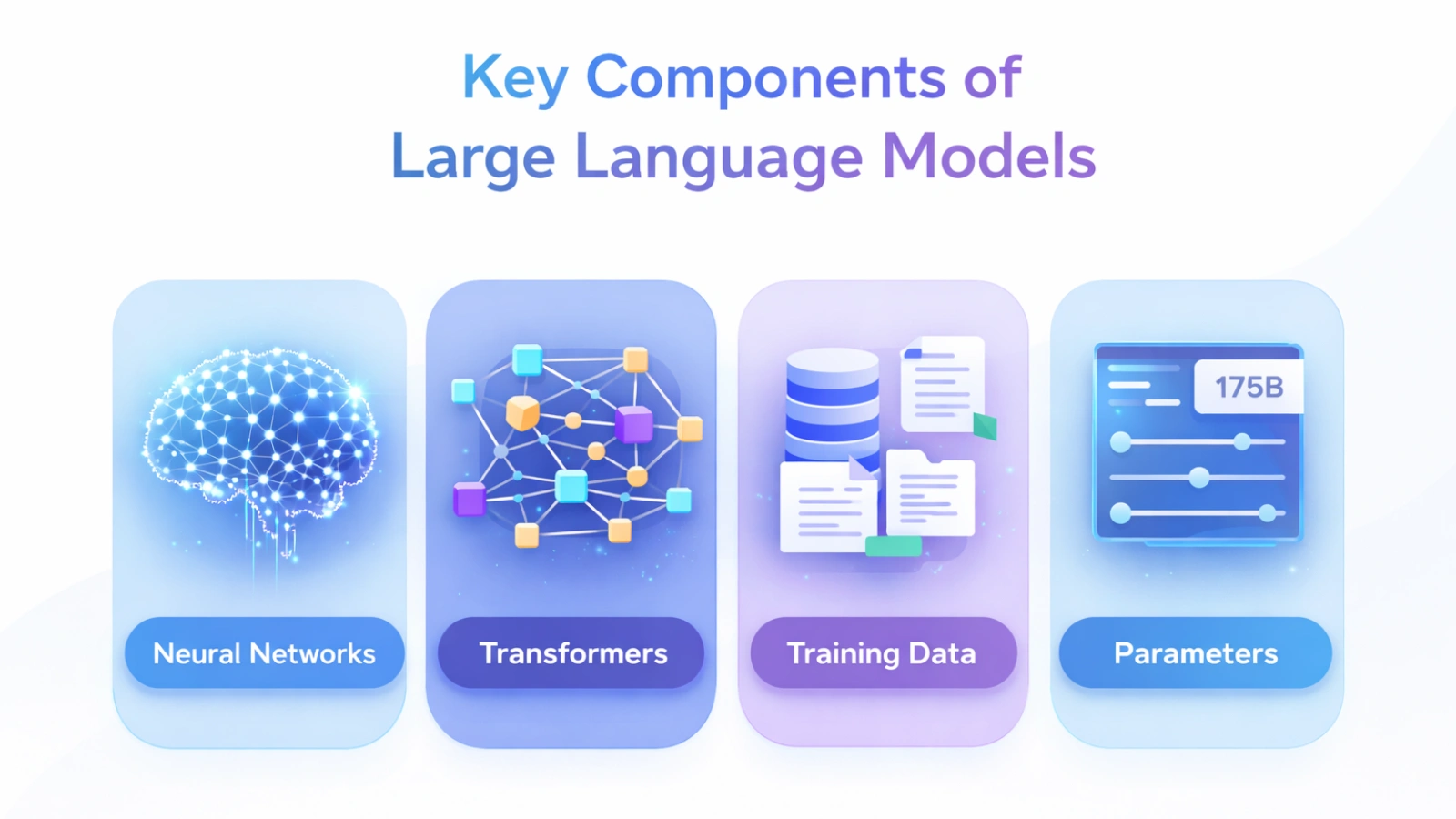
Neural Networks
These networks are the foundation of LLMs. Neural networks are inspired by the human brain and consist of interconnected nodes called neurons, layered to process input data and identify patterns.
Neural networks make LLMs understand how language works by decoding complicated relationships and patterns between words, sentences, and contexts.
Transformers
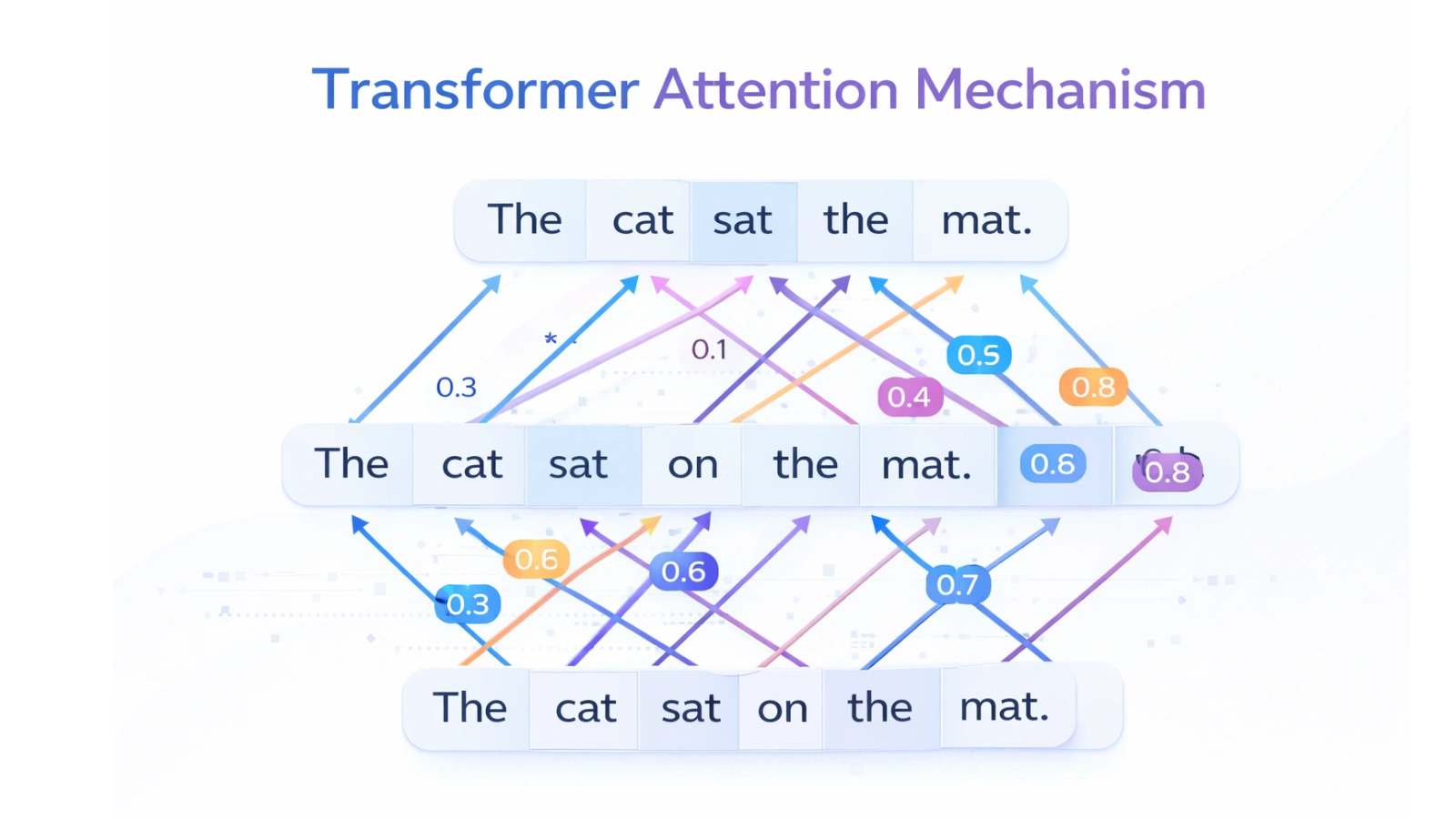
Transformer architecture is what all of the modern-day language models are based on, and they help us to both understand and generate human-like text.
Older sequence models processed each word in isolation (one at a time). But transformers process all words in parallel using a method called attention to assess the relationship between all words and the context they are being used in. This enables the LLM graphic to understand and capture dependencies, subtle meanings, and complex linguistic patterns in a much more effective manner.
A transformer consists of multiple layers that work together to form a stacked series of token embeddings, self-attention, multi-head attention, and feedforward networks. All of these are used to iteratively improve our understanding of the input.
The highly distributable nature of transformers and their ability to scale effectively with both data and computing resources have made them the basis for most large language models.
Transformers are commonly used today, such as in chat applications, machine translation, summarization, and question answering.
Training Data
The efficacy of an LLM also has a great deal to do with an LLM’s training data in terms of the quality and quantity of that data. LLMs use very large datasets that consist of text from a broad range of resources, including, but not limited to, books, newspapers, magazines, journals, websites, and social media.
Data from these sources is used to train large language models on various features of language, such as vocabulary, grammar, and usage in context.
Parameters
The defining characteristic of an LLM is the number of parameters, which are individual internal variables that an LLM learns during training. As the number of parameters used to create a large language model increases, so does the complexity and capability of that model to process textual data.
For example, GPT-5 has over 175 billion parameters and is currently one of the largest and most advanced large language processing models that exist today.
How Do Large Language Models Work?
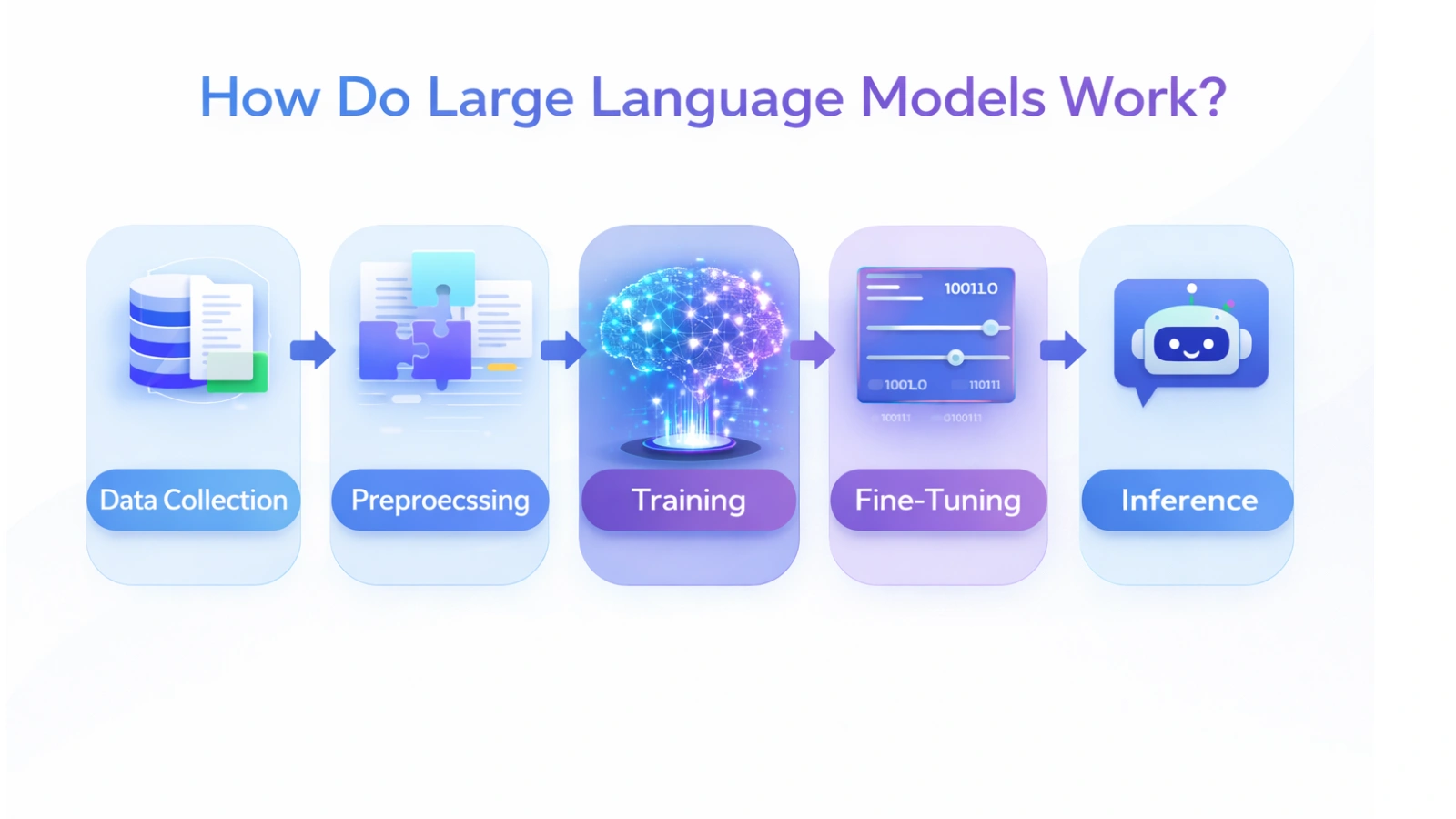
Let us see how an LLM model works:
Data Collection
Training a large language model (LLM) requires multiple steps and a large number of resources. The following are just some of the main parts of the training process.
Preprocessing
The process begins with data collection. This is the gathering of large, diverse datasets that will form the basis of the model’s learning. The dataset needs to be of good quality because the dataset that is being used to formulate the model will greatly influence how well the model can generate and use language.
Model Initialization
The next phase of training in large language models is the preprocessing stage. Once the data is collected, it undergoes a series of transformation processes in order to write usable data for input into the model. Some of these transformation processes include tokenizing the data (breaking the dataset into single words or sub words), cleaning (data free of noise or clutter), and formatting (customizing the data to meet the requirements of the model).
Training
Once the preprocessing stage has been completed, the training starts with an uninitialized neural network (NN). Prior to commencing training, the weights and biases of the neural network were assigned random values, requiring subsequent adjustment as the training occurs to minimize the large language model’s error between predicted and actual output.
Fine-Tuning
Finally, the bulk of neural network training consists of the use of training input and rates of matching predicted output against the actual output. After each cycle of matching (forward propagation), the neural network performs back-propagation, allowing it to calculate the mathematics of the amount of error created by the predicted output vs the model’s final output and perform a set of calculations to adjust and minimize the NN’s previous weight/bias values.
After training the large language model, it can begin making inferences through various mechanisms by taking input and generating text in response.
This is what happens during the inference phase:
Input Prompt
The user submits an input prompt, which will provide the foundation for constructing the response. The type of the input prompt can vary, ranging from a question to a single statement of text to anything else.
Tokenization
The user-provided prompt is broken down into parts, like words that the model can understand as numbers, and used to figure out the next words in the prompt that the user provided. The model uses these parts to make a guess about what comes next in the user-provided prompt. The user-provided prompt is made up of these parts that the model can work with to do its job.
Prediction in large language models
The model performs calculations on the input tokens in order to predict the next token in line, which will be based on the relationships and patterns established during training.
Generation
The model uses the predicted token in the original input prompt provided by the user. It continues this process until it generates a complete response to the prompt while respecting the parameters set by the user (such as temperature and max tokens).
Output
The final resultant output is a complete, contextually relevant response generated from the user-supplied input prompt, utilizing the model for completion.
Challenges of Large Language Models

Ethical and Challenge Issues: While LLMs have great potential, they also have ethical issues and face some challenges that need to be addressed as well.
Bias and Fairness
Large language models may produce unfair content because they learn those harmful patterns from the data they are trained on. We need to find and get rid of these biases in LLMs if we want the things they produce to be fair and unbiased. It is really important to make sure the models do not have biases so that their outputs are fair. Large language models should give us unbiased outputs.
Privacy and Security
By training large datasets
of large language models, there is always a chance that LLMs will remember some private information that could jeopardize an individual’s privacy. We must always ensure user data remains secure and safe when deploying LLMs.
Misinformation and Manipulation
LLMs are capable of generating false information that looks credible and believable, thereby perpetuating misinformation. Therefore, safeguards should be put in place to ensure LLMs are not misused for malicious intents.
Environmental Concerns
LLMs require tremendous amounts of computing power to train, which creates a substantial carbon footprint; thus, it is imperative that we find new and improved ways to create more efficient forms of training LLMs so as to limit their negative environmental impacts.
Transparency and Accountability
As LLMs will have increasing reliance on various applications, we must ensure transparency and accountability regarding LLMs’ decision-making. Users should be able to understand how LLMs function and the limitations of their abilities.
Large Language Model Applications
 There are lots of uses for language models in many areas. Some good examples are:
There are lots of uses for language models in many areas. Some good examples are:
Natural Language Processing
Large Language Models can do things with Natural Language Processing, like figuring out what kind of text something is, finding the names of people and places, and translating languages. NPL needs to be able to understand the languages that people speak so it can get information from them. Natural Language Processing is about working with natural language to make sense of what people are saying.
Content Generation.
Large language models can make a lot of content that’s really good for many different things. They can write articles and marketing copy. They can also compose emails. They can even do creative writing like poetry, scripts, and other forms of storytelling.
Chatbots and Virtual Assistants
Chatbots and virtual assistants are made better by large language models. These LLMs work behind the scenes to help chatbots and virtual assistants talk to people in a way. People can ask chatbots and virtual assistants questions. Get answers. They can also get suggestions for things to buy or use. Chatbots and virtual assistants can even help people do things like book a trip.
Code Generation and Assistance.
Help people who make applications. These tools can understand the basics of programming languages. Assist with finding mistakes, suggesting ways to make the code better, and finishing the code for you.
Education and Tutoring
LLMs can be used as educational tools for providing personalized assistance. This includes responding to student queries, generating educational materials, and assisting with language acquisition.
Using Large Language Models to Enhance Real Business Applications

Understanding the technology behind a large language model is only part of what you need to know when using them in practice. How can businesses apply large language models to their operational processes? Many businesses today are using LLMs to develop intelligent chatbots that provide customer support. They are also beneficial in automating customer service interactions, producing marketing materials, analyzing large amounts of text, improving productivity tools internally, and more.
AI software companies, such as Globussoft, focus on creating AI-enabled software applications and business solutions. These embed capabilities for large language models into an organization’s day-to-day operations through use cases. Such cases include platforms like workforce monitoring productivity, generating marketing materials, creating analytics dashboards, and automating repetitive tasks.
Rather than using a large language model solely for its ability to generate text, implementing large language models in the manner described above connects the language model to available structured data. Whether it be to related business rules or available user workflows to help organizations transition from creating new solutions through experimentation with AI.
Also Read!
How To Choose Between LLM vs Generative AI?
How AI Development Services Are Transforming The Digital Age – Globussoft
Conclusion
To conclude, Large Language Models (LLMs) are an evolving form of artificial intelligence that allows the creation of new capabilities to easily comprehend and create natural forms of communication, such as human language, using extremely precise and fluent methods.
Their efficiency is based on using neural networks, Transformer architectures, and large volumes of training data to produce powerful toolsets with a myriad of uses in today’s economy.
As the research and development of these technologies advance, it is likely that the future holds even more sophisticated models that will change how we work with machines as well as how we process and consume information.
FAQs
Do large language models have intelligence?
The short answer is no, they don’t think as humans do. They are good at recognizing patterns, but they can’t comprehend or have any level of consciousness; their responses are completely dependent upon the training data they were trained on.
Will they take over human jobs?
They do not replace human activities; they augment them. They perform repetitive activities (i.e., writing emails) so that humans can focus on more creative and/or strategic jobs.
Where are they headed?
The future of Large Language Models (LLMs) will bring significant advancement in many areas:
Multimodal AI (integrating image, audio & video)
LLMs will continue to move from just written text to being able to understand and process images, audio & video together. This will allow greater ways for humans to interact with AI.
Hyper-Personalization
LLMs will evolve by personalizing their responses to each individual user based on prior interactions with them. LLMs also deliver unique and tailored responses to users, whether people use them in education, healthcare, or customer service.
Efficiency & Accessibility
LLMs will be smaller and optimized, which will drive down compute costs and therefore lower the cost of using LLMs, making higher levels of AI available at a much larger scale and with a positive effect on the overall environment.
How is LLM useful for businesses?
Large language models are useful tools for businesses. Businesses can use LLMs to do a lot of things. To get the most out of language learning models, businesses should:
- Set clear goals (e.g., automate support, generate content)
- Choose the right approach—ready-made tools or custom-trained models.
- Focus on data quality and security
- Integrate smoothly with existing systems
- Monitor performance and refine continuously
- Work with experts for optimal implementation
Quick Search Our Blogs
Type in keywords and get instant access to related blog posts.
